![[EKL] Elasticsearch란 ?](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fco7WCV%2FbtsH6CoQbhi%2F61cxpjgvDs4UWXnckxmDk0%2Fimg.png)

Elasticsearch란 ?
Elasticsearch는 Apache Lucene(아파치 루씬) 기반의 Java 오픈소스 분산 검색 엔진입니다.
Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이터를 신속하게, 거의 실시간(NRT, Near Real Time)으로 저장, 검색, 분석할 수 있습니다.
Elasticsearch는 검색을 위해 단독으로 사용되기도 하며, ELK(Elasticsearch, Logstatsh, Kibana)스택으로 사용되기도 합니다.
ELK 스택이란 다음과 같습니다 !
Logstash
다양한 소스(DB, csv파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달합니다.
Elasticsearch
Logstash로부터 전달 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 획득할 수 있습니다.
Kibana
Elasticsearch 시각화 툴입니다. Elasticsearch JSON기반 데이터 통신을지원하기에 다양한 클라이언트와 연동이 가능하고, Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링합니다.
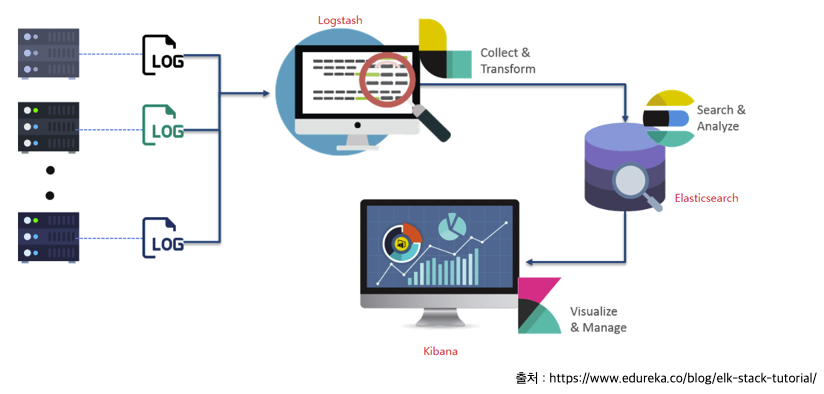
Elasticsearch와 관계형 DB 비교
흔히 사용하고 있는 관계형 DB는 Elasticsearch에서 각각 다음과 같이 대응시킬 수 있습니다.

RDBMS를 사용해보셨던 분들이라면 Elasticsearch에서 사용하는 용어들이 조금 낯설 수 있지만 예제를 몇 번 따라하다보시면 금방 적응하실 수 있을 겁니다 ! 물론 저 또한.....
Elasticsearch 용어 정리

도큐먼트(Document)
RDBMS에서의 row와 비슷하고, Elasticsearch에서 데이터의 최소 단위입니다.
Document는 JSON 객체이며, 다양한 필드를 포함하고, document안에 document가 필드로 존재할 수 있습니다.
필드(Field)
RDBMS에서의 column과 비슷하며, Document안에 들어가는 데이터입니다.
타입(Type)
RDBMS에서의 table과 비슷하며, 여러 Document가 모여서 하나의 type을 이룹니다.
Elasticsearch 6.1부터는 하나의 index(여러 type이 모인 것)당 하나의 type만을 가질 수 있게 되었고, 7.0부터는 type이 사라지고 대신 고정자 _doc으로 접근해야합니다. (ex : "http://localhost:9200/index/_doc1")
인덱스(Index)
데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들로 변환(indexing)하여 저장한 것입니다.
RDBMS의 database와 table의 역할을 하며, 여러 type이 모여 한 개의 index를 이룹니다.
RDBMS에서는 여러 database의 데이터를 한번에 조회할 수 없지만 Elasticsearch에서는 가능합니다.(multitenancy)
index는 shard라는 단위로 분산되어 저장됩니다. Lucene에서 index 파일들은 immutable(불변)하다.
update 시에는 내부적으로 수정될 Document를 삭제 후 다시 inserte합니다. 따라서 수정이 잦은 문서를 Elasticsearch에 저장하는 것은 비효율적입니다.
샤드(Shard)
index가 분산되어 처리되는 단위를 뜻합니다. 각 shard는 물리적 노드들에 나뉘어서 저장되고 shard는 두 종류로 나뉩니다.
- Primary shard : 모든 Document들은 하나의 primary shard에 저장됩니다. Primary shard의 기본 개수는 5개입니다.
- Replica shard : Primary shard의 복제본입니다. 원본 데이터에 fault 발생 시 복구하기 위해 사용됩니다.
Replica shard의 기본 개수는 1개입니다.
노트(Node)
Elasticsearch 클러스터를 구성하는 각각의 Elasticsearch 프로세스들을 의미합니다. 일반적인 클러스터 구조에서 각각의 컴퓨터나 서버들이 노드 역할을 수행하는 것처럼 Elasticsearch 클러스터에서는 각 Elasticsearch 프로세스들이 클러스터를 구성합니다.
세그먼트(Segment)
Segment는 shard가 물리적으로 나뉘어서 저장되는 단위입니다. Document가 처음부터 segment에 저장되는 것은 아닙니다.
indexing된 Document는 먼저 시스템의 메모리 버퍼에 저장되고, 이 때는 Document가 검색되지 않습니다.
Elasticsearch의 refreash 과정을 거쳐야 segment 단위로 physically 저장되고 검색됩니다.
Segment는 immutable(불변)하며, Document가 update 되면 새로운 segment가 생성됩니다. segment가 많아질 수록 검색할 때 성능이 낮아질 수 있습니다. 따라서 Elasticsearch 내부에서 background로 segment merging을 진행합니다.
매핑(Mapping)
Elasticsearch의 index에 들어가는 데이터의 type을 정의하는 것이다. RDBMS에서의 schema와 유사합니다. Elasticsearch는 선 indexing 후 mapping을 지원하며, 새로운 필드가 추가되면 동적으로 해당 필드 indexing 후 mapping까지 해줍니다.
Elasticsearch의 특징
실시간 분석
Elasticsearch는 Hadoop과 같은 배치 기반의 분산 처리 시스템과는 달리 클러스터가 실행되고 있는 동안 데이터가 입력으로 들어오고, 인덱싱이 되며, 실시간에 가까운 속도록 인덱싱된 데이터를 검색, 집계가 가능합니다. 하지만 실제 운영을 했을 때 간헐적으로 많은 request로 인한 HTTP 429에러를 리턴한다고 합니다.
실시간에 가까운 처리가 가능하지만, 모든 request를 실시간으로 처리하기 보단 서비스 구조에서 캐시 레이어를 두고 사용하는 것이 더 안정적인 운영을 할 수 있는 방법인 것 같습니다.
Forward Index

Inverted Index
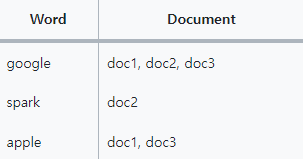
full text에서 특정 문자열을 찾을 때 inverted index 구조의 성능이 매우 좋습니다. 문자열 내의 단어를 key로 검색해서 단어들이 포함된 document를 빠르게 찾을 수 있기 때문입니다 !
RestFull API
Elasticsearch는 모든 데이터 조회, 입력, 삭제를 HTTP 프로토콜을 통해 REST API로 처리합니다.
GET, PUT, POST, DELETE, HEAD 등의 method들이 사용됩니다.
Multitenancy
Elasticsearch의 데이터들은 인덱스라는 단위로 구성되며 분산되어 서로 다른 저장소에 저장됩니다.
서로 다른 인덱스이지만 별도의 커넥션 없이 하나의 쿼리로 묶어서 검색하여 하나의 출력으로 리턴할 수 있습니다.
다같이 열심히 배워봅시다 ! 😆
'개발공부 > Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] elasticsearch 기본 설정 및 cluster 구성하기(start error) (0) | 2024.05.13 |
|---|---|
| [ELK] logstash와 mysql 다중 테이블 가져오기 (0) | 2024.04.25 |
| [EKL] logstash와 Mysql 연동하기 (0) | 2024.04.24 |
| [EKL] Elasticsearch와 kibana 로컬서버에 설치하기 ! (0) | 2024.04.22 |
개발의 모든 것 !
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Elasticsearch] elasticsearch 기본 설정 및 cluster 구성하기(start error)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FecGWlC%2FbtsH52n0vsI%2FgJQuSfB6HkSu04CO2KE8Dk%2Fimg.png)
![[ELK] logstash와 mysql 다중 테이블 가져오기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fo17iu%2FbtsH5Cchaf2%2F09xh12DOMKWSDKKdJVWOL1%2Fimg.png)
![[EKL] logstash와 Mysql 연동하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdC3SA6%2FbtsH6ZKC0Ln%2FKIjylu9zzrDGhTThLkSyt0%2Fimg.png)
![[EKL] Elasticsearch와 kibana 로컬서버에 설치하기 !](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbdsk3i%2FbtsH5B5yuJK%2FEk4CHpTaK42L3AOLRTiQM1%2Fimg.png)